Техника - молодёжи 1998-10, страница 44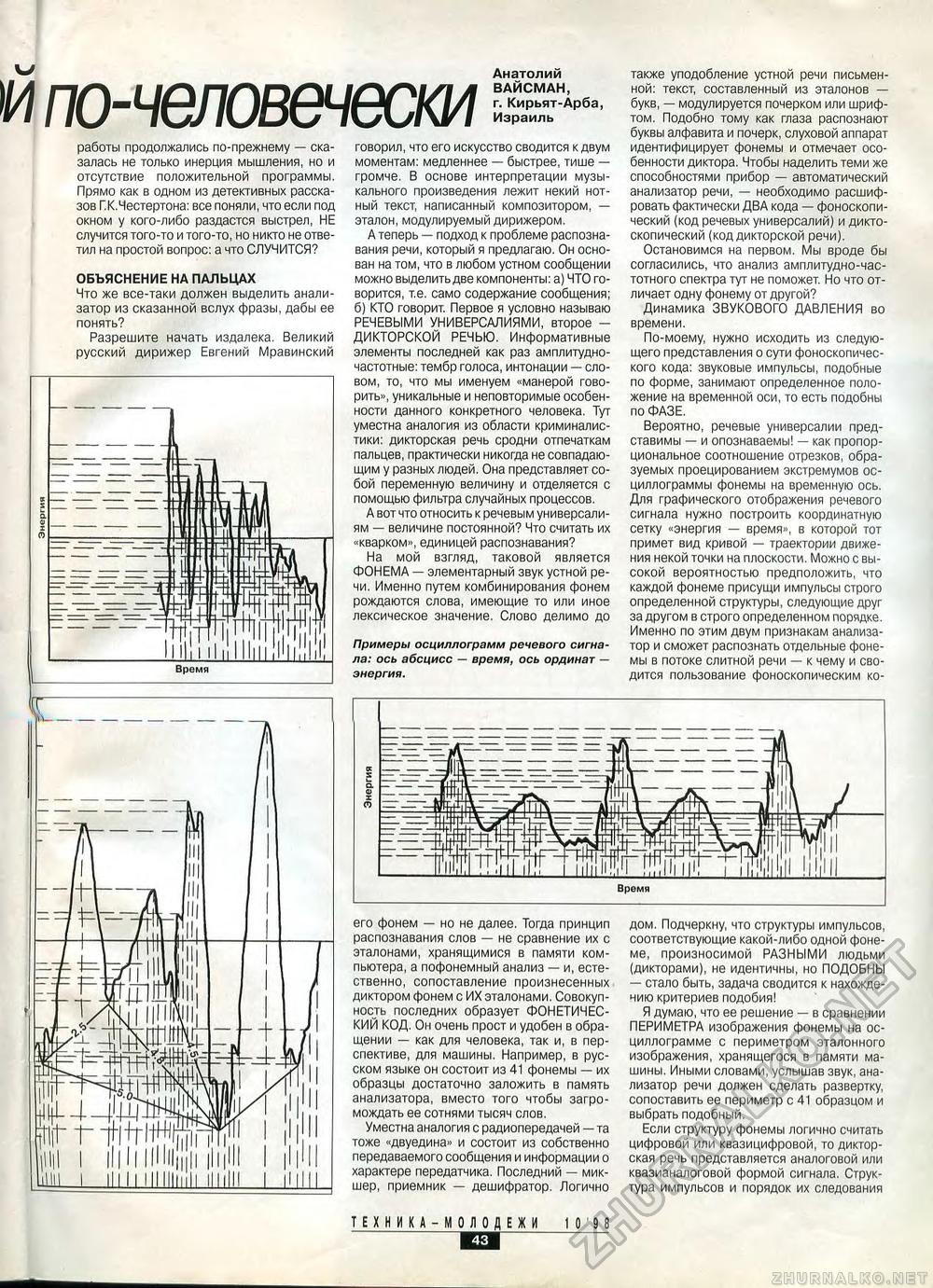
его фонем — но не далее. Тогда принцип распознавания слов — не сравнение их с эталонами, хранящимися в памяти компьютера, а пофонемный анализ — и, естественно, сопоставление произнесенных диктором фонем с ИХ эталонами. Совокупность последних образует ФОНЕТИЧЕСКИЙ КОД. Он очень прост и удобен в обращении — как для человека, так и, в перспективе, для машины. Например, в русском языке он состоит из 41 фонемы — их образцы достаточно заложить в память анализатора, вместо того чтобы загромождать ее сотнями тысяч слов. Уместна аналогия с радиопередачей—та тоже «двуедина» и состоит из собственно передаваемого сообщения и информации о характере передатчика. Последний — микшер, приемник — дешифратор. Логично дом. Подчеркну, что структуры импульсов, соответствующие какой-либо одной фонеме, произносимой РАЗНЫМИ людьми (дикторами), не идентичны, но ПОДОБНЫ — стало быть, задача сводится к нахождению критериев подобия! Я думаю, что ее решение — в сравнении ПЕРИМЕТРА изображения фонемы на осциллограмме с периметром эталонного изображения, хранящегося в памяти машины. Иными словами, услышав звук, анализатор речи должен сделать развертку, сопоставить ее периметр с 41 образцом и выбрать подобный. Если структуру фонемы логично считать цифровой или квазицифровой, то дикторская речь представляется аналоговой или квазианалоговой формой сигнала. Структура импульсов и порядок их следования также уподобление устной речи письменной: текст, составленный из эталонов — букв, — модулируется почерком или шрифтом. Подобно тому как глаза распознают буквы алфавита и почерк, слуховой аппарат идентифицирует фонемы и отмечает особенности диктора. Чтобы наделить теми же способностями прибор — автоматический анализатор речи, — необходимо расшифровать фактически ДВА кода — фоноскопи-ческий (код речевых универсалий) и дикто-скопический (код дикторской речи). Остановимся на первом. Мы вроде бы согласились, что анализ амплитудно-частотного спектра тут не поможет. Но что отличает одну фонему от другой? Динамика ЗВУКОВОГО ДАВЛЕНИЯ во времени. По-моему, нужно исходить из следующего представления о сути фоноскопичес-кого кода: звуковые импульсы, подобные по форме, занимают определенное положение на временной оси, то есть подобны по ФАЗЕ. Вероятно, речевые универсалии пред-ставимы — и опознаваемы! — как пропорциональное соотношение отрезков, образуемых проецированием экстремумов осциллограммы фонемы на временную ось. Для графического отображения речевого сигнала нужно построить координатную сетку «энергия — время», в которой тот примет вид кривой — траектории движения некой точки на плоскости. Можно с высокой вероятностью предположить, что каждой фонеме присущи импульсы строго определенной структуры, следующие друг за другом в строго определенном порядке. Именно по этим двум признакам анализатор и сможет распознать отдельные фонемы в потоке слитной речи — к чему и сводится пользование фоноскопическим ко- ^ Анатолий м по-человечески работы продолжались по-прежнему — сказалась не только инерция мышления, но и отсутствие положительной программы. Прямо как в одном из детективных рассказов ГК.Честертона: все поняли, что если под окном у кого-либо раздастся выстрел, НЕ случится того-то и того-то, но никто не ответил на простой вопрос: а что СЛУЧИТСЯ? ОБЪЯСНЕНИЕ НА ПАЛЬЦАХ Что же все-таки должен выделить анализатор из сказанной вслух фразы, дабы ее понять? Разрешите начать издалека. Великий русский дирижер Евгений Мравинский говорил, что его искусство сводится к двум моментам: медленнее — быстрее, тише — громче. В основе интерпретации музыкального произведения лежит некий нотный текст, написанный композитором, — эталон, модулируемый дирижером. А теперь — подход к проблеме распознавания речи, который я предлагаю. Он основан на том, что в любом устном сообщении можно выделить две компоненты: а) ЧТО говорится, т.е. само содержание сообщения; б) КТО говорит. Первое я условно называю РЕЧЕВЫМИ УНИВЕРСАЛИЯМИ, второе -ДИКТОРСКОЙ РЕЧЬЮ. Информативные элементы последней как раз амплитудно-частотные: тембр голоса, интонации — словом, то, что мы именуем «манерой говорить», уникальные и неповторимые особенности данного конкретного человека. Тут уместна аналогия из области криминалистики: дикторская речь сродни отпечаткам пальцев, практически никогда не совпадающим у разных людей. Она представляет собой переменную величину и отделяется с помощью фильтра случайных процессов. А вот что относить к речевым универсалиям — величине постоянной? Что считать их «кварком», единицей распознавания? На мой взгляд, таковой является ФОНЕМА — элементарный звук устной речи. Именно путем комбинирования фонем рождаются слова, имеющие то или иное лексическое значение. Слово делимо до Примеры осциллограмм речевого сигнала: ось абсцисс — время, ось ординат — энергия. ТЕХНИКА-МОЛ ОДЕЖИ 1098 ки |








